
Journal Club 01 - Transformer Without Normalization (EN)
Published:
This paper challenges the orignial LN by introducing DyT to seek improvement in the realm of transformer.
1. Who
- Authors: Jiachen Zhu • Xinlei Chen • Kaiming He • Yann LeCun • Zhuang Liu
- This paper is a collaboration of researchers from Meta, New York University, Massachusets Institute of Technology (MIT) and Princeton University
2. What
- Main Focus:
- This paper aims to replace the original layer normalization (LN) inspired by recent papers that tried to introduce novel architectures and replace attention layers.
- Key Contributions:
- This paper introduces Dynamic Tanh (DyT) operation as a replacement for normalization layers in Transformers.
- Context in the Field:
- These findings changed the way we understand LN and its role in neural networks
3. Why
- Motivation: This paper challenges the orignial LN by introducing DyT to seek improvement in the realm of transformer.
4. Key Insights
- Important Takeaways:
The idea is quite simple. As the researchers found that LN output exhibit S-shape that is highly resemble that of a tanh function, they introduce tanh function called DyT operation. Equation denoted as DyT(x) = γ * tanh(αx) + β, where α is a learnable parameter. Therefore, they replace traditional LN with DyT.
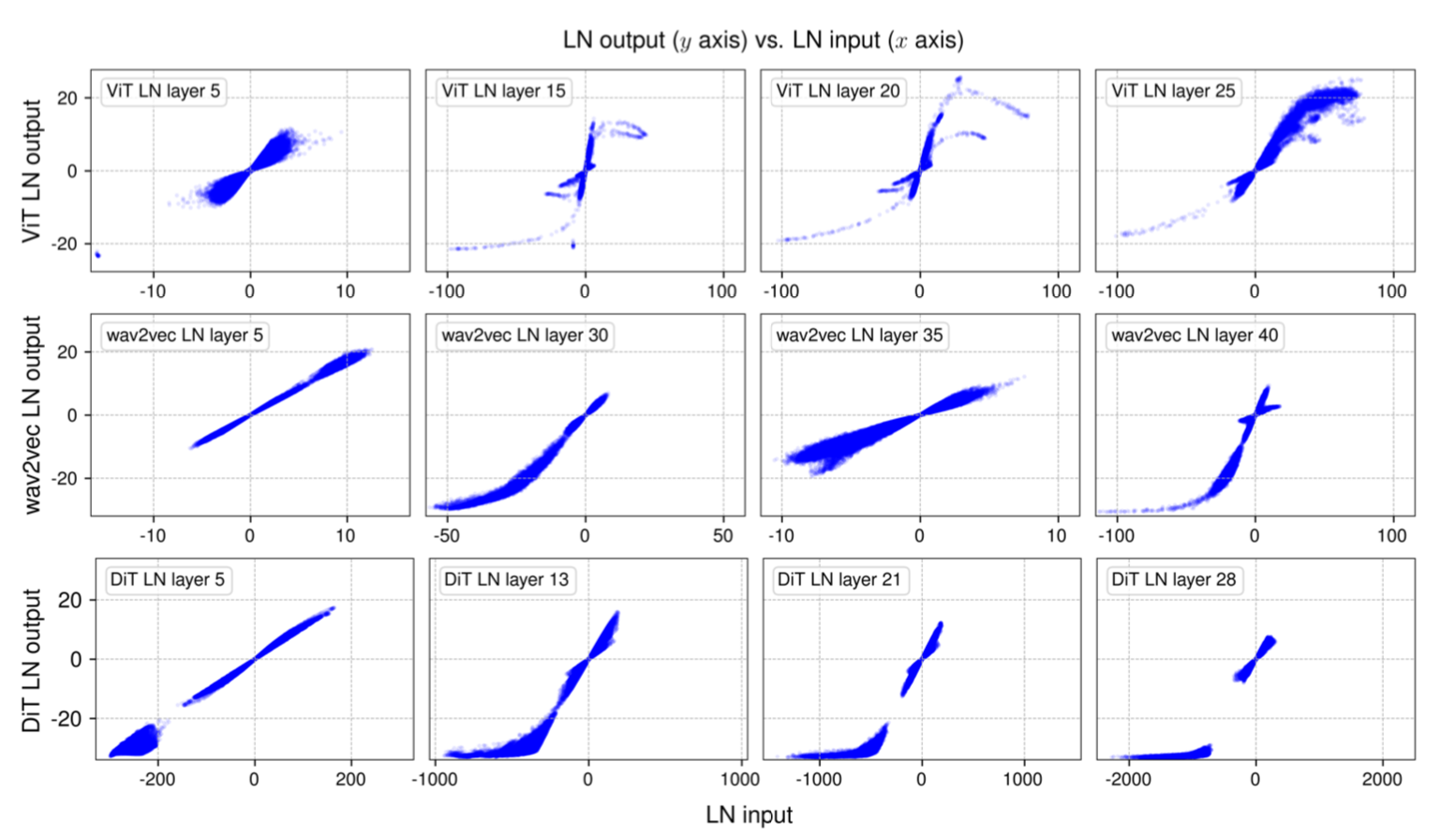
# input x has the shape of [B, T, C] # B = batch size, T = tokens, C = dimension class DyT(Module): def __init__(self, C, init_α): super().__init__() self.α = Parameter(ones(1) * init_α) self.γ = Parameter(ones(C)) self.β = Parameter(zeros(C)) def forward(self, x): x = tanh(self.alpha * x) return self.γ * x + self.βMy area of interest is drug discovery, but this paper has potential to benefit area of research that involves transformer architecture. They tested performance of DyT and LN with Vision Transformer (ViT), diffusion transformer (DiT), large language model (LLM), speech and DNA sequence modelling. The results shows a very subtle improvement, reduction or no change in all comparison. The most interesting part is improved efficiency. LLaMA 8B exhibited 52.4% and 42.2% reduction in inference and training time respectively. In conclusion, DyT match or exceed the performance of LN but largely improve LLM inferencing and training time.
5. Critical Analysis
- Strengths:
- Explannation is clear, simple and straight-forward
- Limitations or Open Questions:
- Despite magnificent result in improved efficiency of DyT in LLM training pipeline, the paper does not illustrate other use cases such as image generation.
6. Practical Implications
- Real-World Applications:
- I had experience in fine-tuning model for medical task before. So, with DyT, training and inferencing are expected to be faster.
7. Next Steps
- Future Research or Applications:
- This paper will be useful for those who wants to create their own transformer model. Aside from DyT function that replaces LN, this paper also explore the role of LN in transformer.
Paper Link/DOI: arXiv.2503.10622 