
JC04 - Reflect, Retry, Reward
Published:
LLM ตัวเล็กเอาชนะตัวใหญ่ได้ยังไง? นักวิจัยเผยวิธีใหม่ที่ทำให้ LLM ตัวเล็กสามารถทำงานได้ดีกว่า LLM ที่ใหญ่กว่า ถึง 10 เท่า วันนี้ผมมีเปเปอร์ที่น่าสนใจมากสำหรับ Journal Club ในวันนี้ “Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning ที่ช่วยให้ LLM เรียนรู้จากความผิดพลาดของตัวเองได้อย่างชาญฉลาด!
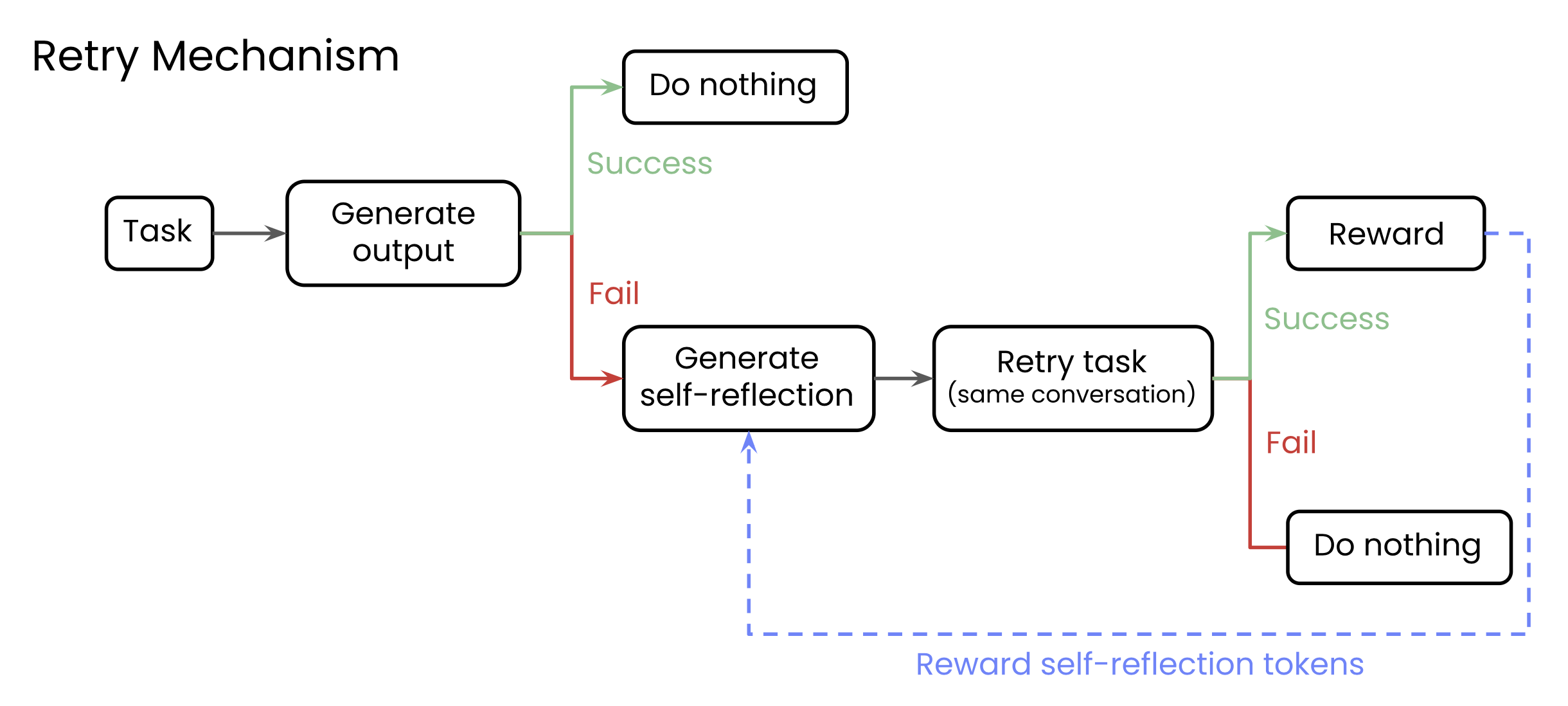
กลไก “Reflect, Retry, Reward” ทำงานอย่างไร? นี่คือขั้นตอนง่ายๆ ของเทคนิคนี้:
- ทำภารกิจ: โมเดลลองทำภารกิจตามที่ผู้ใช้สั่ง
- พลาด & สะท้อนคิด: หากโมเดลทำผิด (ตรวจสอบได้ด้วยการให้คะแนนแบบ “ถูก/ผิด” หรือไบนารี) โมเดลจะถูกกระตุ้นให้สร้าง self-reflection วิเคราะห์ว่าอะไรผิดพลาด
- ลองอีกครั้ง: โมเดลจะพยายามทำภารกิจเดิมอีกครั้ง โดยครั้งนี้จะมี self-reflection ที่สร้างขึ้นมาจากขั้นตอนก่อนหน้า
- ให้รางวัล: ถ้าการพยายามครั้งที่สองสำเร็จ เฉพาะ tokens in the self-reflection เท่านั้นที่จะได้รับรางวัล โดยใช้ Reinforcement Learning แบบ GRPO เป้าหมายคือสอนให้โมเดล “สะท้อนคิด” ได้ดีขึ้นโดยรวม ไม่ใช่แค่แก้ปัญหาเฉพาะหน้า!
ผลลัพธ์ที่น่าทึ่ง! ประสิทธิภาพเพิ่มขึ้นอย่างเห็นได้ชัด:
- เพิ่มขึ้นสูงสุด 34.7% ในการเขียนสมการคณิตศาสตร์
- เพิ่มขึ้นสูงสุด 18.1% ในการเรียกใช้ฟังก์ชัน (Function Calling)
- ที่สำคัญคือ โมเดลขนาดเล็กที่ผ่านการฝึกฝนด้วย GRPO สามารถทำได้ดีกว่าโมเดลขนาดใหญ่ที่ไม่ได้รับการฝึกฝน แม้จะมีขนาดต่างกันถึง 10 เท่า! เช่น Qwen-2-7B Instruct ที่ผ่านการฝึก ดีกว่า Qwen-2-72B Instruct ที่ไม่ผ่านการฝึกในการเรียกใช้ฟังก์ชัน
ทำไมวิธีนี้ถึงมีประสิทธิภาพสูง?
- พัฒนาการให้เหตุผลโดยรวม: หลังการทดลอง โมเดลดูเหมือนจะพัฒนาทักษะการให้เหตุผลโดยทั่วไป ซึ่งเป็นประโยชน์แม้ไม่ต้องสะท้อนคิดในครั้งแรก
- บทสะท้อนคิดที่ดีขึ้น: หลังการฝึกด้วย GRPO โมเดลจะสร้าง self-reflection ที่ สั้น กระชับ ชัดเจน และนำไปใช้ได้ทั่วไปมากขึ้น ซึ่งแตกต่างจากสไตล์ Chain-of-Thought ที่มักจะยาวกว่า
- ไม่เกิด Catastrophic Forgetting: วิธีนี้ช่วยให้โมเดลยังคงรักษาความสามารถในการทำงานอื่นๆ ได้ดี และไม่ลืมสิ่งที่เคยเรียนรู้ไปแล้ว
Paper: arXiv:2505.24726
